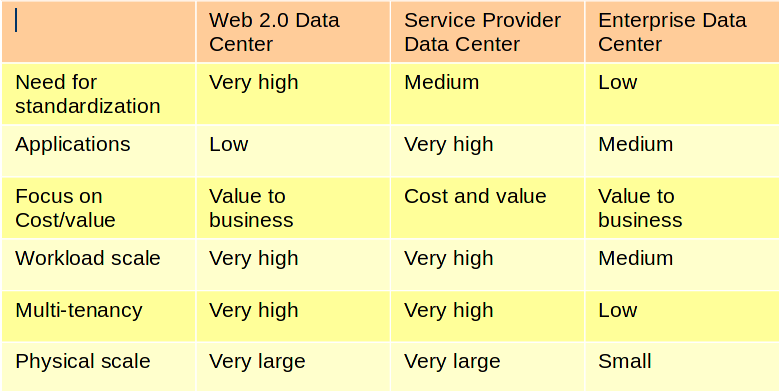
If you read some papers such as this, you will see that it is a bit hard to beat custom ASICs for packet routing at line rate when compared to general purpose x86 ASICs. So, how do we make the networking world more open like the server world, given this constraint? If we see the x86 world, what is standardized is an ISA (Instruction Set Architecture) on top of which layers upon layers of multi-source stacks have been built.
Is it possible to standardize such an ISA for custom ASICs? Even though they are custom, all of the ASICs (whether they are closed ASICs from Cisco, Brocade or commodity ASICs from Broadcom, Cavium etc.) do one specific thing – network related processing. Given this, is it not possible to standardize the ISA? May be it is not so straight forward to achieve this, so people ended up with things such as openflow to standardize the interface to the hardware layer.
Anyways, the article linked above (by James Hamilton) gives a very good contrast of what happened in the server world and where we are in the networking world and how it is moving). As Cumulus guys said, history does not repeat, but does rhyme! 🙂